









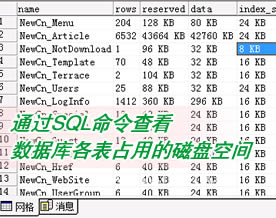
关于查看各表占用的空间的命题在SQL Server 2005中,微软特别发布了一个报表,可供直接查看。但在SQL Server 2…


核心提示:在复杂的数据中心基础设施中,这种能力可以让你通过丰富的经验和自身的知识快速而准确地发现问题之所在。这种能力只可意会,不可言传。没有人会提供和“超自然故障排除”有关的认证的。
但是,那些重量级的问题解决专家都会遵守一些通用的,不成文的规则。这是我自己使用的六个规则。注意,它们适用于大多数情况,但是并不是所有情况。
1、永远不要修改服务器或网络设备的连接接口
虽然这听上去很简单,但是,令人吃惊的是,人们经常会修改他们用于连接到某个设备的网络接口的属性,这种行为的失败率很高。有时,这条规则可能是可选的,但是,如果有一种方法可以排除潜在的隐患,何乐而不为呢?如果你不得不修改这个接口,可以在这个接口上配置一个辅助IP(secondaryIP)——通过另外一个设备或子网,串行控制台,KVM等来连接。如果设备放在远程的办公室里(那里没有IT职员),那么这绝对是一条真理。
2、保证总是有办法回到原点
无论何时,只要有可能的话,都要提供一种可以把问题恢复到原始状态的方法。这意味着,在对故障磁盘做任何修改以前,应该为这个故障磁盘做一个映像,备份整个目录结构(你不可能知道你以后需要哪些文件,这样可以以防万一),或者,在你胡乱摆弄一个已经出现故障的操作系统以前,应该在物理服务器上抽取出这块磁盘的RAID1阵列。当然,在虚拟机环境下,这会更加容易一些,因为你可以简单地做一个快照。
3、文档,文档,还是文档
在所有这些规则中,这条规则也许是大家最少遵守的规则了。毫无疑问,应该把一个问题和解决方法文档化。当你处在混乱状态之中的时候,你的解决方法也许并不明智。这就是说,当一个问题尘埃落定以后,要保留一份“尸检报告”,通过这份报告,你可以重新检查当时那个解决方案采取的步骤和途径。把它写下来,然后把它保存在安全的地方,最好是放到公司内部的wiki上;并且,应该备份到几个不同的地方。
4、在IT领域,不存在魔法,但是却存在幸运
就像ThomasJefferson说的那样:“我发现我工作的越努力,我就越幸运。”在IT领域,也是这样的。你花费越多的时间来研究你的基础设施,关注路由器,交换机,服务器和其他设备的特定的工作条件,你的基础设施就会运行的越流畅。这些日常工作可以让你在问题的早期阶段就发现这些问题,当问题真的发生的时候,你可以更加快速地作出反应。另外,在IT领域,有很多种方法可以“制造”幸运。例如,使用一些工具,让网络设备配置的备份自动化;如果使用这种方法的话,当你的交换机发疯的时候,你可以在几分钟内恢复它,而不是几个小时。
5、在你修改每个配置文件以前,要对它们进行备份
这条规则只适用于Unix服务器和几乎各方面的配置都提供了配置文件的网络设备。在你弄坏敏感的配置以前,首先对交换机和TFTP(TrivialFileTransferProtocol)主机的配置文件进行备份。在Unix系统上,可以简单地把something.confcp到something.conf.orig。
在必要的时候,如果想恢复到过去那个良好的状态,只需要简单地把文件拷贝回去,然后重启那个服务就可以了。因为注册表的存在和Windows喜欢把简单的概念复杂化,所以,在Windows系统上,这通常是不可能的。即便如此,你还是可以在胡乱摆弄注册表以前,对注册表进行备份,这样的话,如果天下大乱了。你可以重新导入备份的注册表文件。记住:当你对Windows注册表进行修改的时候,服务器的生命就掌握在你的手中。
6、监控,监控,还是监控
一点点预防工作就可以省去一个月的周末加班时间。你应该对你的数据中心的方方面面进行监控,从房间的温度,机架,和服务器,到服务器进程检查,正常运行时间检查......你还应该为所有网络设备构建一个集中式的日志系统,除此之外,你还应该安装一些趋势分析工具来监控带宽利用率,温度,磁盘空间的使用率,和其他的参数。当这些参数超过正常的阀值的时候,那些监控工具应该通过必要的手段来通知你。

