









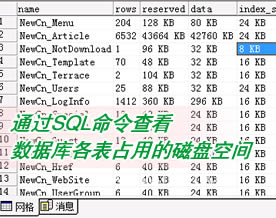
关于查看各表占用的空间的命题在SQL Server 2005中,微软特别发布了一个报表,可供直接查看。但在SQL Server 2…

内容提示:文章主要描述的是SQL Server索引密度(Index Densities),当一个查询的SARG 的值直到查询运行时才得以知晓,或是SARG是一个关于索引的多列时,SQL Server才使用为索引中每列存储的密度值。
对于组合键值,SQL Server为第一列的组合键存储了密度值;为第一列和第二列;为第一、二、三列;等等。这些信息可以从Listing34.1的DBCC SHOW_STATISTICS 输出信息的All density区域看到。
SQL Server索引密度表示为键的唯一键值的倒数。每个键的密度可以按照下面的公式进行计算:
Key density = 1.00/ ( Count of distinct key values in the table
键密度 = 1.00 / (表中的不同键值数)
所以,pubs数据库的author表中state列的密度计算公式如下:
Sql代码
Select Density = 1.00/
(select count (distinct state) from authors)
Go
Select Density = 1.00/
(select count (distinct state) from authors)
Go
Density .1250000000000
State和zip的组合列密度计算如下:
Sql代码
Select density = 1.00/
( select count (distinct state + zip) from authors)
Go
Select density = 1.00/
( select count (distinct state + zip) from authors)
Go Density .0555555555555
注意,不像选择率,越小的SQL Server索引密度意味着具有更高的索引选择性。当密度趋近于1,索引就变得有更少的选择性,基本上没有用处了。当索引的选择性低的时候,优化器可能会选择一个表扫描(table scan),或者叶子级的索引扫描(Index scan),而不会进行索引查找(index seek),因为这样会付出更多的代价。
当心你的数据库中低选择性的索引。这样的索引通常是对系统的性能是一个损害。它们通常不仅不会用来进行数据的检索,而且也会使得数据修改语句变得缓慢,因为需要额外的索引维护。识别这些索引,考虑删除掉它们。
通常,当你给键中添加更多的列时,密度值应该变得更小。例如,在Listing 34.2,密度值逐渐变小。
Key Column Index Density
title_id 1.8621974E-3
title_id, stor_id 5.997505E-6
title_id, stor_id, ord_num 5.9268041E-6
以上的相关内容就是对SQL Server索引密度(Index Densities)的介绍,望你能有所收获。

