摘要:随着因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题(它可以为用户提供信息检索服务)。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。…
随着因特网的迅猛发展、WEB信息的增加,用户要在信息海洋里查找信息,就象大海捞针一样,搜索引擎技术恰好解决了这一难题(它可以为用户提供信息检索服务)。目前,搜索引擎技术正成为计算机工业界和学术界争相研究、开发的对象。
搜索引擎(Search Engine)是随着WEB信息的迅速增加,从1995年开始逐渐发展起来的技术。据发表在《科学》杂志1999年7月的文章《WEB信息的可访问性》估计,全球目前的网页超过8亿,有效数据超过9T,并且仍以每4个月翻一番的速度增长。用户要在如此浩瀚的信息海洋里寻找信息,必然会“大海捞针”无功而返。
搜索引擎正是为了解决这个“迷航”问题而出现的技术。搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。搜索引擎提供的导航服务已经成为互联网上非常重要的网络服务,搜索引擎站点也被美誉为“网络门户”。搜索引擎技术因而成为计算机工业界和学术界争相研究、开发的对象。本文旨在对搜索引擎的关键技术进行简单的介绍,以起到抛砖引玉的作用。
- 分类 按照信息搜集方法和服务提供方式的不同,搜索引擎系统可以分为三大类: 1.目录式搜索引擎: 以人工方式或半自动方式搜集信息,由编辑员查看信息之后,人工形成信息摘要,并将信息置于事先确定的分类框架中。信息大多面向网站,提供目录浏览服务和直接检索服务。该类搜索引擎因为加入了人的智能,所以信息准确、导航质量高,缺点是需要人工介入、维护量大、信息量少、信息更新不及时。这类搜索引擎的代表是:Yahoo、LookSmart、Open Directory、Go Guide等。2.机器人搜索引擎: 由一个称为蜘蛛(Spider)的机器人程序以某种策略自动地在互联网中搜集和发现信息,由索引器为搜集到的信息建立索引,由检索器根据用户的查询输入检索索引库,并将查询结果返回给用户。服务方式是面向网页的全文检索服务。该类搜索引擎的优点是信息量大、更新及时、毋需人工干预,缺点是返回信息过多,有很多无关信息,用户必须从结果中进行筛选。这类搜索引擎的代表是:AltaVista、Northern Light、Excite、Infoseek、Inktomi、FAST、Lycos、Google;国内代表为:“天网”、悠游、OpenFind等。3.元搜索引擎: 这类搜索引擎没有自己的数据,而是将用户的查询请求同时向多个搜索引擎递交,将返回的结果进行重复排除、重新排序等处理后,作为自己的结果返回给用户。服务方式为面向网页的全文检索。这类搜索引擎的优点是返回结果的信息量更大、更全,缺点是不能够充分使用所使用搜索引擎的功能,用户需要做更多的筛选。这类搜索引擎的代表是WebCrawler、InfoMarket等。
- 性能指标 我们可以将WEB信息的搜索看作一个信息检索问题,即在由WEB网页组成的文档库中检索出与用户查询相关的文档。所以我们可以用衡量传统信息检索系统的性能参数-召回率(Recall)和精度(Pricision)衡量一个搜索引擎的性能。召回率是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统(搜索引擎)的查全率;精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统(搜索引擎)的查准率。对于一个检索系统来讲,召回率和精度不可能两全其美:召回率高时,精度低,精度高时,召回率低。所以常常用11种召回率下11种精度的平均值(即11点平均精度)来衡量一个检索系统的精度。对于搜索引擎系统来讲,因为没有一个搜索引擎系统能够搜集到所有的WEB网页,所以召回率很难计算。目前的搜索引擎系统都非常关心精度。影响一个搜索引擎系统的性能有很多因素,最主要的是信息检索模型,包括文档和查询的表示方法、评价文档和用户查询相关性的匹配策略、查询结果的排序方法和用户进行相关度反馈的机制。
0收 藏
您的每一点爱心都是我们成长的动力

支付宝扫一扫赞助

微信钱包扫描赞助
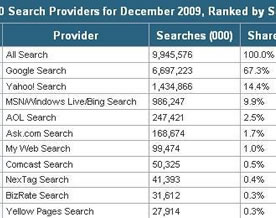
根据市场调研公司Nielsen最新发布的12月份美国搜索引擎市场排名,12月份的用户使用搜索引擎次数接近100亿,Google以超…