









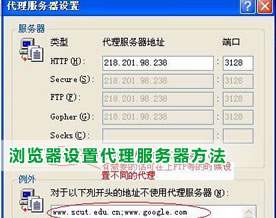
本文将详细介绍IE、Maxthon、GreenBrowser、Firefox四种常用浏览器的上网代理设置方法。…

二、基本处理流程
通过分析现有技术,可以归纳出以下几个解决该问题的核心技术点,每个不同的技术基本上是由这几个技术点构成,无非是具体采纳的技术不同而已:
1.文档对象的特征抽取:将文档内容分解,由若干组成文档的特征集合表示,这一步是为了方面后面的特征比较计算相似度.
2.特征的压缩编码:通过HASH编码等文本向数字串映射方式以方便后续的特征存储以及特征比较.起到减少存储空间,加快比较速度的作用.
3.文档相似度计算:根据文档特征重合比例来确定是否重复文档.
4.聚类算法:通过叠代计算算出哪些文档集合是根据相似度计算是相近的;
5.工程化问题:出于海量数据计算速度的考虑,提出一些速度优化算法以使得算法实用化.
我们可以从几个不同的角度对于现有的方法进行分类:
按照利用的信息,现有方法可以分为以下三类
1.只是利用内容计算相似
2.结合内容和链接关系计算相似
3.结合内容,链接关系以及url文字进行相似计算
评价:现有绝大部分方法还是利用文本内容进行相似识别,其它两种利用链接关系以及URL文字的方法还不是很成熟,而且从效果看引入其它特征收效并不明显,所以从实际出发还是选择利用内容进行相似计算的算法.
按照特征提取的粒度现有方法可以分为以下三类
1.按照单词这个级别的粒度进行特征提取.
2.按照SHINGLE这个级别的粒度进行特征提取.SHNGLE是若干个连续出现的单词,级别处于文档和单词之间,比文档粒度小,比单词粒度大.
3.按照整个文档这个级别的粒度进行特征提取
评价:
目前这个领域里面很多工作借鉴类似于信息检索的方法来识别相似文档,其本质和SHINGLE等是相同的,都是比较两个文档的重合程度,但是区别是SHINGLE是将若干单词组成片断,粒度比较大,而信息检索类方法其实是用单词作为比较粒度,粒度比较小,粒度越大计算速度越快,而粒度越小计算速度越慢,所以信息检索类方法是不实用的,而且对SHINGLE的改进以及新提出的方法的发展趋势也是粒度越来越大,这样才能解决实际使用中速度的问题。粒度最大的极端情况是每个文档用一个HASH函数编码(比如MD5),这样只要编码相同就说明文档完全相同,但是粒度太大带来的问题是对于细微的变化文档无法判别,只能判断是否完全相同,至于部分相同以及相同的程度无法判断.
所以,现有方法也可以从以下角度分类:粒度。最小粒度:单词;中等粒度:SHINGLE;最大粒度:整个文档;可见SHINGLE类方法其实是在速度和精确程度上的一种折中方法。可以探讨不同粒度的效果,比如以句子为单位进行编码,以段落为单位编码等不同粒度的编码单位,还可以考虑动态的编码:首先以自然段落编码进行判别,如果发现部分相似,然后针对不同的部分再以细小粒度比如句子甚至单词级别的比较 所谓SUPER SHINGLE就是将粒度放大得到的。粒度越大,好处是计算速度越快(对于MD5整个文档来说,每个文档一个HASH编码,然后排序,将相同的找出,是速度最快的),缺点是会遗漏很多部分相似的文档;粒度越小,好处是招回率比较高,缺点是计算速度减慢。

