









电子商务和信息技术的快速发展及对它的需求给应用程序开发人员带来了新的压力。必须以比以前更少的金钱、更少的资源来更快地设计、建立和生…

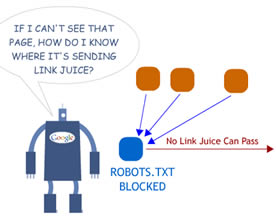
前两天刚知道用爬虫抓取page有个协议的问题,尤其是对于open source的爬虫,刚看到一篇blog,写的就是如此,难怪之前看google的robots也和另外一个U.S.的网站相同,感情是大家都商量好了,可能这方面中国的一些站点这种意识要稍微淡一点。。。同时这也害得毕设还得另谋思路。。。
搜索引擎三巨头打的不亦乐乎,但偶尔也合作一下。去年Google,雅虎,微软就合作,共同遵守统一的Sitemaps标准。前两天三巨头又同时宣布,共同遵守的 robots.txt文件标准。Google,雅虎,微软各自在自己的官方博客上发了一篇帖子,公布三家都支持的robots.txt文件及Meta标签的标准,以及一些各自特有的标准。下面做一个总结。
三家都支持的robots文件记录包括:
Disallow - 告诉蜘蛛不要抓取某些文件或目录。如下面代码将阻止蜘蛛抓取所有的网站文件:
User-agent: *
Disallow: /
Allow - 告诉蜘蛛应该抓取某些文件。Allow和Disallow配合使用,可以告诉蜘蛛某个目录下,大部分都不抓取,只抓取一部分。如下面代码将使蜘蛛不抓取ab目录下其他文件,而只抓取其中cd下的文件:
User-agent: *
Disallow: /ab/
Allow: /ab
$通配符 - 匹配URL结尾的字符。如下面代码将允许蜘蛛访问以.htm为后缀的URL:
User-agent: *
Allow: .htm$
*通配符 - 告诉蜘蛛匹配任意一段字符。如下面一段代码将禁止蜘蛛抓取所有htm文件:
User-agent: *
Disallow: /*.htm
Sitemaps位置 - 告诉蜘蛛你的网站地图在哪里,格式为:Sitemap: <sitemap_XXXXXX>
三家都支持的Meta标签包括:
NOINDEX - 告诉蜘蛛不要索引某个网页。
NOFOLLOW - 告诉蜘蛛不要跟踪网页上的链接。
NOSNIPPET - 告诉蜘蛛不要在搜索结果中显示说明文字。
NOARCHIVE - 告诉蜘蛛不要显示快照。
NOODP - 告诉蜘蛛不要使用开放目录中的标题和说明。
上面这些记录或标签,现在三家都共同支持。其中通配符好像以前雅虎微软并不支持。百度现在也支持Disallow,Allow及两种通配符。Meta标签我没有找到百度是否支持的官方说明。
只有Google支持的Meta标签有:
UNAVAILABLE_AFTER - 告诉蜘蛛网页什么时候过期。在这个日期之后,不应该再出现在搜索结果中。
NOIMAGEINDEX - 告诉蜘蛛不要索引页面上的图片。
NOTRANSLATE - 告诉蜘蛛不要翻译页面内容。
雅虎还支持Meta标签:
Crawl-Delay - 允许蜘蛛延时抓取的频率。
NOYDIR - 和NOODP标签相似,但是指雅虎目录,而不是开放目录。
Robots-nocontent - 告诉蜘蛛被标注的部分html不是网页内容的一部分,或者换个角度,告诉蜘蛛哪些部分是页面的主要内容(想被检索的内容)。
MSN还支持Meta标签:Crawl-Delay
另外提醒大家注意的是,robots.txt文件可以不存在,返回404错误,意味着允许蜘蛛抓取所有内容。但抓取robots.txt文件时却发生超时之类的错误,可能导致搜索引擎不收录网站,因为蜘蛛不知道robots.txt文件是否存在或者里面有什么内容,这与确认文件不存在是不一样的。

