










在当今这个数字化时代,人工智能的应用已经贯穿到我们的生活中的各个方面,尤其是在实现人机交互方面,ChatGPT(Generativ…


【抽象层的改变】
以前,硬件/软件边界由 ISA 定义,并且该内存是连续可寻址的。而涉及到多处理器时,一般内存定义也是也是一致的。但是可以想象,在数据流引擎中,一致性并不那么重要,因为数据会从一个加速器直接传到另一个加速器。
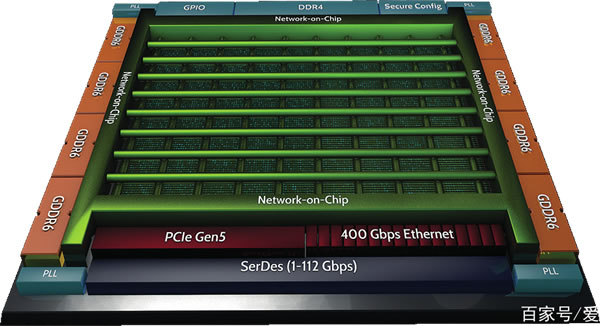
如果你对数据集进行分区,那一致性会成为障碍,你需要对照和更新数据,并会占用额外的运算周期。所以我们需要,也必须考虑不同的内存结构,毕竟可用的内存就那么点。或许可以访问相邻的内存,但也会很快耗尽,然后无法及时访问。所以必须在设计中加以理解,而且是要在理解架构的情况下去设计它。
我们还需要更高级别的抽象层。有些框架可以将已知网络映射或编译到目标硬件上,例如在一组低级内核或 API,它们将在软件堆栈中使用,并最终由神经网络的映射器使用。在底层,你可能在用不同类型的硬件,这由你想要实现的目标来决定。反正就是用不同的硬件,不同的 PPA ,实现了相同的功能。
而这会给编译器带来很大的压力。主要的问题是你未来要如何对加速器进行编程?你是否搞了个像初代 GPU 那样串在一起的硬连线引擎?或者你是否构建了具有自己指令集的小型可编程引擎?现在你必须单独对这些东西进行编程,并将这些引擎中的每一个都与数据流连接起来,然后执行任务。
一个处理器拥有整个指令集的某个子集,另一个处理器拥有一个不同的子集,它们都将共享控制流的某些重叠部分,编译器得了解它的库并进行映射。

