









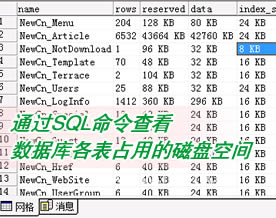
关于查看各表占用的空间的命题在SQL Server 2005中,微软特别发布了一个报表,可供直接查看。但在SQL Server 2…

11、说明:几个高级查询运算词
A: UNION 运算符
UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行。两种情况下,派生表的每一行不是来自 TABLE1 就是来自 TABLE2。
B: EXCEPT 运算符
EXCEPT 运算符通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表。当 ALL 随 EXCEPT 一起使用时 (EXCEPT ALL),不消除重复行。
C: INTERSECT 运算符
INTERSECT 运算符通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表。当 ALL 随 INTERSECT 一起使用时 (INTERSECT ALL),不消除重复行。
注:使用运算词的几个查询结果行必须是一致的。
12、说明:使用外连接
A、left outer join:
左外连接(左连接):结果集几包括连接表的匹配行,也包括左连接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUTER JOIN b ON a.a = b.c
B:right outer join:
右外连接(右连接):结果集既包括连接表的匹配连接行,也包括右连接表的所有行。
C:full outer join:
全外连接:不仅包括符号连接表的匹配行,还包括两个连接表中的所有记录。
其次,大家来看一些不错的sql语句
1、说明:复制表(只复制结构,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1<>1
法二:select top 0 * into b from a
2、说明:拷贝表(拷贝数据,源表名:a 目标表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;
3、说明:跨数据库之间表的拷贝(具体数据使用绝对路径) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具体数据库’ where 条件
例子:..from b in '"&Server.MapPath(".")&"\data.mdb" &"' where..
4、说明:子查询(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)
5、说明:显示文章、提交人和最后回复时间
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
21、说明:列出表里的所有的
select name from syscolumns where id=object_id('TableName')
22、说明:列示type、vender、pcs字段,以type字段排列,case可以方便地实现多重选择,类似select 中的case。
select type,sum(case vender when 'A' then pcs else 0 end),sum(case vender when 'C' then pcs else 0 end),sum(case vender when 'B' then pcs else 0 end) FROM tablename group by type
显示结果:
type vender pcs
电脑 A 1
电脑 A 1
光盘 B 2
光盘 A 2
手机 B 3
手机 C 3
23、说明:初始化表table1
TRUNCATE TABLE table1
24、说明:选择从10到15的记录
select top 5 * from (select top 15 * from table order by id asc) table_别名 order by id desc
随机选择数据库记录的方法(使用Randomize函数,通过SQL语句实现)
对存储在数据库中的数据来说,随机数特性能给出上面的效果,但它们可能太慢了些。你不能要求ASP“找个随机数”然后打印出来。实际上常见的解决方案是建立如下所示的循环:
Randomize
RNumber = Int(Rnd*499) +1
While Not objRec.EOF
If objRec("ID") = RNumber THEN
... 这里是执行脚本 ...
end if
objRec.MoveNext
Wend
这很容易理解。首先,你取出1到500范围之内的一个随机数(假设500就是数据库内记录的总数)。然后,你遍历每一记录来测试ID 的值、检查其是否匹配RNumber。满足条件的话就执行由THEN 关键字开始的那一块代码。假如你的RNumber 等于495,那么要循环一遍数据库花的时间可就长了。虽然500这个数字看起来大了些,但相比更为稳固的企业解决方案这还是个小型数据库了,后者通常在一个数据库内就包含了成千上万条记录。这时候不就死定了?
采用SQL,你就可以很快地找出准确的记录并且打开一个只包含该记录的recordset,如下所示:
Randomize
RNumber = Int(Rnd*499) + 1
SQL = "SELECT * FROM Customers WHERE ID = " & RNumber
set objRec = ObjConn.Execute(SQL)
Response.WriteRNumber & " = " & objRec("ID") & " " & objRec("c_email")
不必写出RNumber 和ID,你只需要检查匹配情况即可。只要你对以上代码的工作满意,你自可按需操作“随机”记录。Recordset没有包含其他内容,因此你很快就能找到你需要的记录这样就大大降低了处理时间。

