









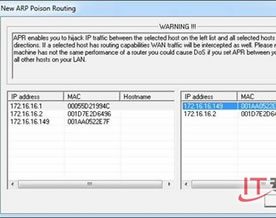
本系列将讨论最常被使用的中间人攻击形式,包括ARP缓存中毒攻击(ARP Cache Poisoning)、DNS欺骗(DNS Sp…

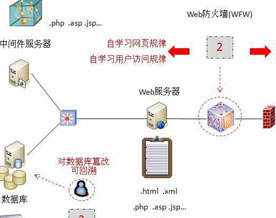
上部分内容请见:专家解读:Web安全原理与技术分析(上)
四、Web安全产品分析
围绕Web服务的安全,产品可以说五花八门,最基本的是接入网入口的UTM网关,其中IPS功能与防DDOS功能是Web服务器系统级入侵的直接防护,但UTM是通用的边界安全网关,非“专业的”Web入侵防护,一般作为安全的入门级防护,这里不细说。这里主要分析专为Web服务开发的安全产品,大概有下面几方面的产品:
1、网页防篡改产品:
防护未知攻击是难的,但看好我自己的“家底”是相对容易的。因此,人们最先想到的就是网页防篡改技术,保持自己的“纯洁”,起码对社会不会造成大危害。网页被篡改产品出现在Web早期,几经风雨,各厂家技术逐渐统一。网页防篡改技术的基本原理:是对Web服务器上的页面文件(目录下文件)进行监控,发现有更改及时恢复。所以该产品实际是一个“修补”的工具,不能阻止攻击者的篡改,就来个守株待兔,专人看守,减少损失是目标,防篡改属于典型的被动防护技术。
网页防篡改产品的部署:建立一台单独的管理服务器(Web服务器数量少可以省略),然后在每台Web服务器上安装一个Agent程序,负责该服务器的“网页文件看护”,管理服务器是管理这些Agent看护策略的。
我们先分析一下“页面文件看护”技术的变迁:
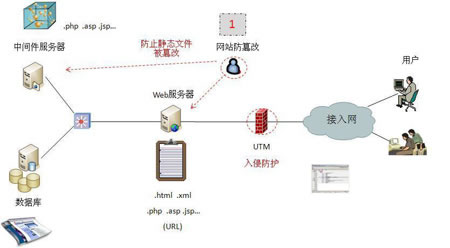
a)第一代技术,把Web服务器主目录下的文件做一个备份,用一个定时循环进程,把备份的文件与服务使用的文件逐个进行比较,不一样的就用备份去覆盖。网站更新发布时,则同时更新主目录与备份。这种方法在网站大的情况下,网页数量巨大,扫描一遍的时间太长,并且对Web服务器性能也是挤占。
b)第二代技术,采用了Hash算法,对主目录下的每个文件做Hash,生成该文件的“指纹”,定时循环进程直接计算服务用文件的Hash指纹,然后进行指纹核对,指纹一般比较小,比较方便;指纹具有不可逆的特点,不怕仿制。
c)第三代技术,既然网站上页面太多,三级以下页面的访问量,一般使用呈指数级下降,没人访问当然也不会被篡改,在这些页面重复扫描是不划算的。改变一下思路:对文件读取应该没有危险,危险的是对文件的改写操作。若只对文件被改变时才做检查,就可以大大降低对服务器资源的占用;具体做法是:开启一个看守进程,对Web服务器的主目录文件删改操作进行监控,发现有此操作,判断是否有合法身份,是否为授权的维护操作,否则阻断其执行,文件不被改写,也就起到了网页防篡改的目的。这个技术也称为事件触发防篡改。
这种技术需要考验对服务器操作系统的熟悉程度,但黑客也是高手,你的看护进程是用户级的,黑客可以获得高级权限,绕过你的“消息钩子”,监控就成了摆设。
d)第四代技术,既然是比谁的进程权限高,让操作系统干这个活儿,应该是最合适的,黑客再牛也不可能越过操作系统自己“干活”。因此,在Windows系统中,提供系统级的目录文件修改看护进程(系统调用),防篡改产品直接调用就可以了,或者利用操作系统自身的文件安全保护功能,对主目录文件进行锁定(Windows对自己系统的重要文件也采取了类似的防篡改保护,避免病毒的侵扰),只允许网站发布系统(网页升级更新)才可以修改文件,其他系统进程也不允许删改。
这个方法应该说比较彻底,但可以看出,以后防篡改技术将成为操作系统的“专利”了,安全厂家实在是不愿意看到的。好在目前Linux还没有支持。
网页防篡改系统可以用于Web服务器,也可以用于中间件服务器,其目的都是保障网页文件的完整性。
网页防篡改对保护静态页面有很好的效果,但对于动态页面就没有办法了,因为页面是用户访问时生成的,内容与数据库相关。很多SQL注入就是利用这个漏洞,可以继续入侵Web服务器。
到目前为止,很多网页防篡改产品中都提供了一个IPS软件模块,用来阻止来针对Web服务的SQL注入、XML注入攻击。如国内厂家的WebGuard、iGuard、InforGuard等产品。

